


テキスト処理入門:Pythonで高速な辞書を作ろう(その1)

目次
[その1]
[その2]
[その3]
[その4]
テキスト処理(text processing)の重要性
高電社開発室の川上と申します。
現在、ニューラルネットワークを使った自然言語処理が盛んです。
高電社でも、従来のルールベース翻訳(RBMT)・統計翻訳(SMT)で培った技術を活かしつつ、
ニューラルネットワークの応用タスクであるニューラル翻訳(NMT)に取り組んでいます。
自然言語処理の世界において、縦糸となる重要な技術はテキスト処理(text processing)です。
今回はテキスト処理の入門として、ある程度Pythonをご存じの方を対象に、辞書プログラムの
作り方をご紹介します。なるべくシンプルな実装で、かつ実用的なものを目指します。
本記事のプログラム例では、Python 3.6.xをjupyter-notebook上で使っています。
辞書引きとは何か(本記事がカバーする内容について)
辞書引きプログラムの目的は、あるテキストデータ(例えばWikipediaの記事)から、
目的の文字列(見出し語;例えばWikipediaの見出しの文字列)を検索することです。
以下、話を簡単にするために見出し語との完全一致検索を考えることにします。
テキストデータを検索し、あらかじめ辞書に登録した見出し語の文字列がヒットしたら
あらかじめ登録しておいた語義を表示するわけです。この語義については、
データベース(特にkey-value storeのような非リレーショナルデータベース)に
保存しておくことが考えられます。これは別の機会に譲るとして、今回は
前半の「検索」のみに焦点を当て、検索インデックスの仕組みを見て行きます。
注)「もうだいたい分かっているので、プログラミングの話だけ読みたい」という方は、
以下の話は飛ばして「ダブル配列のPythonによる実装(1)」からどうぞ。
Trie木(trie)の基本的な考え方
文字列の一致検索と言えば、まずは連想配列(associative array)が思い浮かびます。
Python標準のdictもそうですね。もう1つ、押さえておきたいのが、今回のテーマである
Trie木(trie)です。Pythonの標準ライブラリには入っていませんので作ってみましょう。
では、いきなりですがTrie木の例を下図に示します。「*」が語末の目印です。
いくつ単語が格納されているか、数えてみましょう。
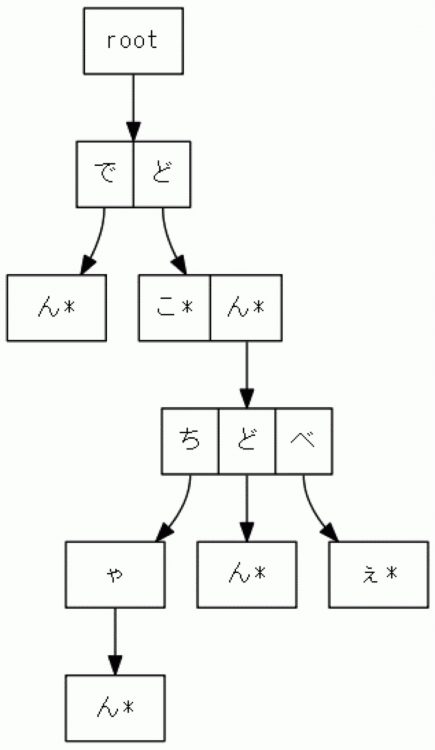
rootから「*」までをたどってみましょう。
「でん」「どこ」「どん」「どんちゃん」「どんどん」「どんべぇ」と6単語ありますね。
「↓」の先が子供のノード(node)で次の文字を表し、隣同士くっついているマスは
兄弟のノードで同じ位置の文字の選択肢を表します。
厳密には「あるノードが文字データによって次のノードに遷移する」と考えるので、
文字データは矢印(edge)のところに書きます。(その辺りは学術書をご覧ください)
さらに実装を楽にするために、二分木にしてみます。
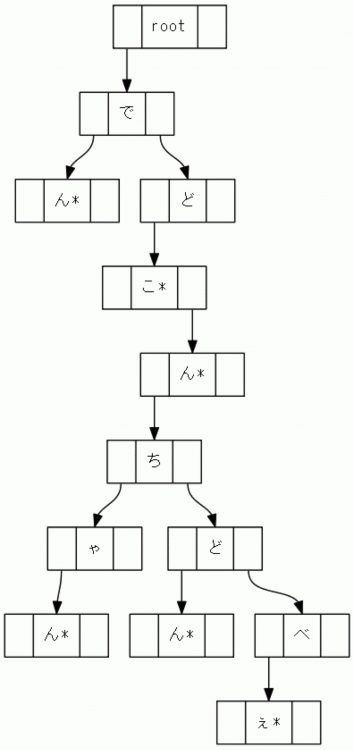
人間にとっては最初の図より分かりにくいですが、基本は同じです。この図のTrie木では、
左側の「↓」の先が子供のノード、右側の「↓」の先が兄弟のノードになっています。
また、「*」が付いたノードは葉ノード(leaf node)と呼びます。
このようにrootから葉ノードまで次々と文字を検索することで、辞書引きが出来ます。
実装を考えてみましょう。まずノードのクラスを作ります。メンバとして:
・左ノードのインデックス番号
・右ノードのインデックス番号
・ノードが持つ文字データ(もしくはその文字コード)
・葉ノードの時は語義のデータレコードの番号(葉ノードでない時は例えば-1)
以上があれば良さそうです。次にTrie木のクラスを作ります。
まずノード(上図のやり方では13個)は配列で持つことにしましょう。
あとは、Trie木へのノードの登録と検索のメソッドを書けば完成です(?)
こんな素朴な設計・実装でも、高速な検索が可能で、自然言語処理の様々なタスクに
充分に役立ちます。私も膨大なテキストデータを扱う際などは、良くPythonやC++11で
このようなTrie木のプログラムを書いて活用していました。
ダブル配列(double array)について
さて、ここからが本題です。Trie木には様々な設計や実装があります。
現在の主流は、ダブル配列(double array)と呼ばれるアルゴリズムです。
提唱されたのは20数年前と歴史がありますが、理解の敷居が少し高かったこともあり、
近年までは「玄人好みの道具」みたいな扱いだったと思います。
今は、とても分かりやすく噛み砕いた解説が読めるので、一般の人達(平たく言えば
私のような普通の理解力の持ち主)でも手が届く技術になっています。
「情報系修士にもわかるダブル配列」
http://d.hatena.ne.jp/takeda25/20120219/1329634865
ウェブでも読める分かりやすい解説記事では、この方がパイオニアです。
「形態素解析の理論と実装」
https://www.amazon.co.jp/dp/4764905779
形態素解析のバイブル本。第4章に数ページですが素晴らしい解説があります。








